


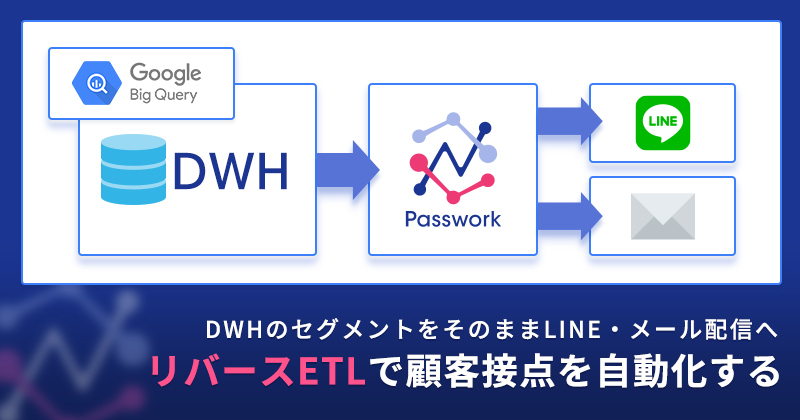
データウェアハウスに、せっかく「優良顧客」「離反しかけ」「カゴ落ち」のセグメントを溜めたのに、見て終わりになっていませんか。BIで切り出したリストを、人が手でCSVに落として、LINEやメール配信ツールに入れ直す ── この最後のひと手間が、施策のスピードを律速します。PassworkのリバースETLは、DWHのセグメントをそのままLINE(公式アカウント)やSendGridのメール配信へ自動で流し込み、顧客接点を仕組みで回します。
データは溜まったのに、なぜ顧客に届かないのか
この数年で、多くの企業がデータ基盤の整備に投資しました。BigQueryやRedshiftにデータが集まり、Tableauで顧客をきれいにセグメント分けできるようになった ── ここまでは、確かに前進です。
ところが、現場でよく聞くのはこんな声です。
「ダッシュボードで『3か月買っていない離反予備軍が1,200人』って出てるんです。でも、その人たちに実際にフォローのメッセージを送るところは、結局担当者がCSVをエクスポートして、LINEの管理画面にアップして……っていう手作業。だから、施策が月1回くらいしか回らない」
ここに、データ活用の最後の断絶があります。分析基盤は「データを集めて、見る」ところまでは自動化されました。しかし、その示唆を顧客への一通のメッセージに変えるところは、いまだに人の手作業に残されているのです。
セグメントは、見るために作ったのではありません。その人に、ちょうどいいタイミングで、ちょうどいい一言を届けるために作ったはずです。なのに、最後のひと手間が重くて、施策の頻度が落ちる ── これは、いちばんもったいない詰まり方です。

ここに私たち Prazto は問いを立てました:
分析の終点であるセグメントを、そのまま顧客接点の起点にできないか? 人がCSVを運ぶのではなく、データ基盤から配信チャネルまでを一本のフローでつなげないか?
リバースETLとは ── 「分析の終点」を「接点の起点」に変える
この詰まりを解く考え方が、リバースETL(Reverse ETL)です。言葉は新しく聞こえますが、発想はとてもシンプルです。
通常のETLは、各業務システム(SFA・POS・広告など)からデータウェアハウスへ「集める」方向の流れです。リバースETLは、その逆 ── データウェアハウスで磨き上げたセグメントや顧客属性を、業務側のツールへ「戻す」方向の流れを指します。
| 観点 | 通常のETL(集める) | リバースETL(戻す・届ける) |
|---|---|---|
| 流れの向き | 業務システム → DWH | DWH → 業務システム・配信ツール |
| 目的 | 分析できる状態に集約する | 分析の結果を「行動」に変える |
| 運ぶもの | 生データ・トランザクション | 磨いたセグメント・スコア・属性 |
| 受け取る側 | BI・データ分析基盤 | LINE・メール・SFA・広告など現場の接点 |
つまりリバースETLとは、「DWHの中で完結していた分析」を、現場の顧客接点まで届ける配管です。せっかく作った「離反予備軍」のセグメントが、ダッシュボードの数字で終わらず、その人のLINEに届く一通のメッセージになる ── その橋渡しを担います。
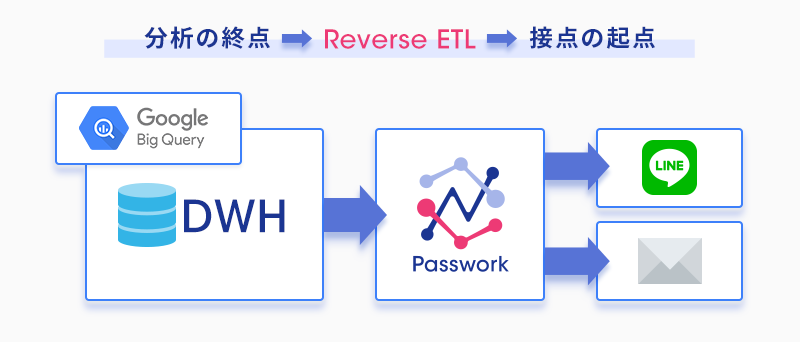
リバースETLは、新しい分析手法ではありません。すでにある分析結果を「使える形で外に出す」ための仕組みです。だからこそ、データ基盤に投資した企業ほど、ここを自動化したときの効果が大きくなります。眠っている資産に、出口を一本通すイメージです。
手作業のCSV配信 vs リバースETLで自動化された顧客接点
「セグメントをCSVに落として配信ツールに入れる」という手作業と、PassworkのリバースETLで組む自動化 ── 何が決定的に違うのでしょうか。
| 観点 | 手作業のCSV配信 | PassworkのリバースETL |
|---|---|---|
| セグメント抽出 | 担当者がBIから手でエクスポート | DWHのクエリ結果を自動で取得 |
| 配信頻度 | 人が動いた時だけ(月1回など) | 毎日・毎朝でも自動でトリガー |
| チャネル振り分け | ツールごとに手でリストを作り直す | 同じフローからLINE・メールへ出し分け |
| ミスの混入 | 古いCSV・宛先ズレ・二重送信 | 最新データで毎回同じ条件で配信 |
| 個別化 | 全員に同じ文面が精一杯 | セグメントの属性で文面を差し込み |
| 資産性 | 毎回ゼロから手作業 | 一度組めば回り続ける施策の仕組み |
違いは「楽になる」だけではありません。本質は、施策を「人が思い出した時にやるイベント」から「毎日勝手に回る仕組み」へ変えるという設計判断です。頻度が上がれば、タイミングの精度も上がります。
実例:DWHのセグメントをLINEとメールに出し分ける
具体的なシーンで動きを見てみましょう。ECサイトで、DWH(BigQuery)に溜めた顧客セグメントを、LINE公式アカウントとメール(SendGrid)の2チャネルに自動で配信するケースです。
① DWHのセグメントを起点にする
まず、データウェアハウス上でセグメントを定義します。たとえば、こんなテーブルが日次で更新されているとします。
| customer_id | segment | preferred_channel | last_purchase |
|---|---|---|---|
| C-10245 | 離反予備軍 | line | 2026-03-02 |
| C-10288 | カゴ落ち | 2026-06-11 | |
| C-10301 | 優良顧客 | line | 2026-06-10 |
これは「分析の成果物」です。これまでは、このテーブルを見て、人がCSVに落としていました。リバースETLでは、このテーブルそのものがフローの入力になります。
② Passworkでフローを組む
入力ノードにDWH(BigQuery等)を置き、preferred_channel の値で分岐させて、LINEコネクタとSendGridコネクタの2つの出力ノードへ流します。あとはスケジュール実行で、毎朝自動で回り続けます。
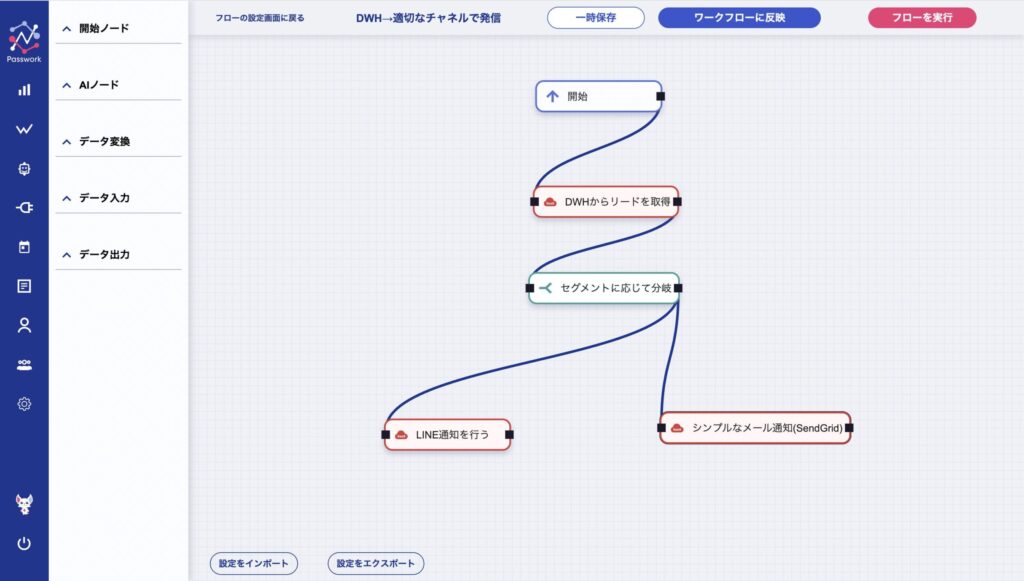
③ チャネルごとに、最適な接点で届く
同じセグメントでも、顧客が普段使うチャネルへ届けられます。LINEが開封されやすい層にはLINEで、メールで丁寧に伝えたい層にはメールで ── という出し分けが、一本のフローで完結します。
これまで月1回、担当者がCSVを運んでやっと送っていた施策が、フローを一度組んで以降は、人の手が一切入らない状態になります。古いリストを送ってしまう事故も、宛先のズレも消えます。
なぜ「人手のひと手間」が施策を止めるのか
ここで一歩引いて、構造を見てみます。「CSVを落として配信ツールに入れる」── 作業自体は、ほんの15分かもしれません。では、なぜそれが施策の頻度を律速するのでしょうか。
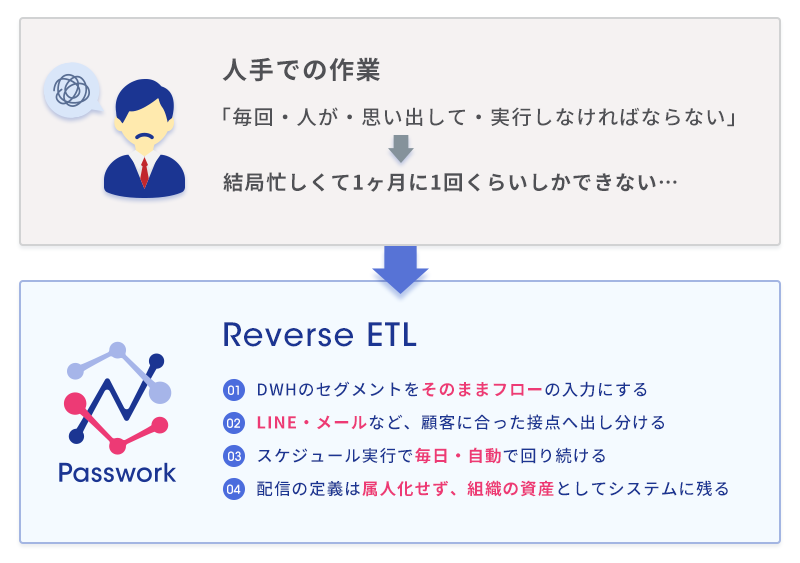
理由は、その15分が「毎回・人が・思い出して・実行しなければならない」性質だからです。15分の作業でも、それが人のタスクである限り、優先度の高い別の仕事に押されて後回しになります。気づけば「今月もキャンペーン打てなかった」が続く ── これが現場の実態です。
施策の頻度を決めるのは、アイデアの量ではなく「実行のコスト」です。一回あたりの手間がゼロに近づくほど、施策は気軽に・頻繁に打てるようになります。リバースETLが本当に効くのは、作業時間の削減そのものより、「打とう」と思った瞬間に打てる状態を作るからです。
そして、人手のCSV運用にはもう一つの隠れたコストがあります。属人化です。「あのセグメントの抽出条件」「どのツールに入れるか」「どの文面か」── これらが担当者の頭の中にだけ溜まり、その人が抜けると再現できなくなります。フローに組んでおけば、配信の定義そのものが組織の資産としてシステムに残ります。
1回15分の作業を、月1回から毎日に増やすことはできません。しかし、その作業をゼロにすれば、頻度は人の都合から解放されます。これが、最後のひと手間を仕組みに移す意味です。
配信の先 ── 決定論とAIエージェントの役割分担
顧客接点の自動化には、性質の違う2つの判断が混ざっています。Passworkは、ここを明確に切り分けます。
決定論で固めるべきところ
「どのセグメントを、どのチャネルに、いつ送るか」── この配信ルールは、毎回同じ結果が保証されるべき領域です。気まぐれで宛先が変わっては困ります。だからこそ、フロー上に明示的に定義し、決定論的に・確実に回します。誰がいつ実行しても同じ ── これが信頼の土台です。
AIエージェントに任せられるところ
一方で、「このセグメントの人に、いま何と言うのが響くか」という文面づくりや、配信結果を見ての打ち手の調整は、AIが力を発揮する領域です。正規化済みのセグメントデータという確かな土台があってはじめて、AIは安全に「気の利いた一言」を考えられます。
「AIに顧客対応を任せれば勝手にうまくやる」── そう単純ではありません。鍵は、AIの賢さよりもその手前のデータ整備と、確実に届ける配管にあります。顧客を理解し(業務理解)、DWHと配信ツールに接続し(業務接続)、毎回同じ条件で確実に配信する(決定論の整備)── この地味な土台づくりこそ、Praztoが最も得意とする領域です。AIは、その上で初めて武器になります。
リバースETLは、この「決定論の配管」を担う部分です。AIが考えた一言を、ちゃんと正しい相手に、確実に届ける ── その最後のラストワンマイルを、仕組みとして保証します。
まとめ:分析を、届くところまで自動化する
データ基盤への投資で、私たちは「データを集めて、見る」ところまでは自動化してきました。しかし、その示唆を顧客への一通のメッセージに変える最後のひと手間は、いまだに人の手作業に残されています。
セグメントは見るために作ったのではなく、届けるために作ったはずです。にもかかわらず、CSVを運ぶ人手の作業が、施策の頻度を月1回に縛り、定義を担当者の頭の中に閉じ込めてきました。
PassworkのリバースETLは、この最後の断絶を埋めます。
- DWHのセグメントを そのままフローの入力にする
- LINE・メールなど、顧客に合った接点へ出し分ける
- スケジュール実行で 毎日・自動で回り続ける
- 配信の定義は 属人化せず、組織の資産としてシステムに残る
これは「配信を少し楽にする便利機能」ではありません。ダッシュボードで眠っていたセグメントに出口を通し、「打とう」と思った瞬間に打てる状態を作る ── そのための、分析から接点までを一本でつなぐ仕組みです。



