


データ連携の項目マッピングは、長らく 「白紙から1つずつ対応付ける」 作業でした。Passworkの「マッピング自動提案」は、その起点を変えます ── AIが下書きを書き、人間はそれを承認する。本記事では、ドラフトファーストという新しい働き方と、なぜ「下書き止まり」がいちばん正しい設計なのかをお話しします。
「白紙のマッピング表」という、地味で重い負担
データ連携を一度でも自分の手で組んだことがある人なら、この画面を覚えているはずです ── 左に入力フィールド、右に出力フィールド、間はぜんぶ空白。この「白紙のマッピング表」を、上から順に埋めていく作業です。
1行ずつ「これはどこに対応するんだっけ」と確認し、命名規則の違いを頭の中で翻訳し、型を気にしながら線を引いていく。フィールドが30個あれば30回、100個あれば100回。知的な判断はほとんど発生しないのに、集中力だけは確実に削られていく作業です。
難しいのではなく、「ただ多い」こと。1つ1つは数秒で判断できるのに、それが何十回も続くから疲れる。そして疲れた後半ほど、見落としや取り違えが混ざる ── マッピングミスの多くは、難しい行ではなく「単調さに負けた行」で起きます。
ここで立ち止まって考えたいのは、「この作業は、本当に白紙から始める必要があるのか?」 という問いです。
多くの場合、フィールド名・型・実際の値を見れば、対応関係の大半は機械的に推測できます。「Name」と「customer_name」が同じものだろう、という判断は、人間がやってもAIがやっても結論はほぼ同じ。だとすれば ── 最初の一稿は、人が書かなくてもいいのではないか。
作業の起点が変わる ── ドラフトファーストという発想
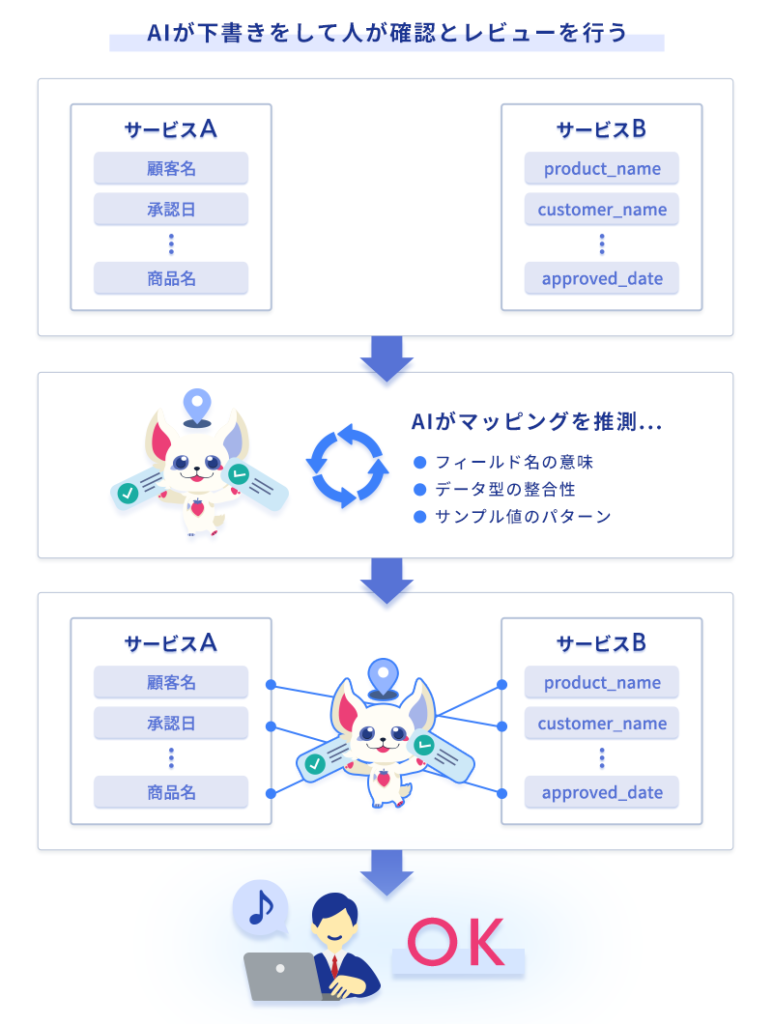
Passworkの「マッピング自動提案」がやっていることを一言で言えば、「白紙を、下書き済みの状態に変える」ことです。
文章を書くときのことを思い出してください。真っ白なページに最初の一文を書くのと、誰かが書いた草稿を直すのとでは、心理的な重さがまるで違います。直す作業には「叩き台」という出発点があり、人は「ここは合ってる、ここは違う」と判断するだけでいい。0→1ではなく、0.8→1の仕事になるのです。
マッピングもまったく同じです。AIが先にひととおり対応付けを埋めておけば、人間の作業は 「ゼロから対応を考える」から「提案された対応をチェックする」へ と質的に変わります。
| 観点 | 白紙から書く(従来) | 下書きを直す(自動提案) |
|---|---|---|
| 作業の起点 | 何も書かれていない空欄 | AIが埋めた一稿(ドラフト) |
| 人間の動作 | 対応関係を考えて入力する | 提案の正否を判断する |
| 判断の単位 | 全フィールドを等しく考える | 確信度の低い箇所に集中できる |
| 疲労の質 | 単調な反復で集中力が落ちる | 確認とレビューに頭を使える |
| ミスの出方 | 後半の見落としで混入 | 怪しい行が最初から可視化される |
「速くなる」のは結果であって、本質ではありません。本質は 作業の起点が「白紙」から「下書き」に動いたこと。起点が変わると、人間が向き合う問いそのものが「どう埋めるか」から「これで合っているか」に変わります。
AIは何を根拠に「下書き」を書くのか
「AIが勝手に埋める」と聞くと、名前が似ているだけの雑なマッチを心配されるかもしれません。Passworkの自動提案は、そうした粗い判定ではなく、3つの根拠を組み合わせて下書きを書きます。
- フィールド名の意味
「顧客名」「customer_name」「Account.Name」── 表記が違っても意味が同じものを、意味ベースで対応付けます。日本語と英語が混ざっていても、命名規則がバラバラでも問題ありません。
- データ型の整合性
「文字列の郵便番号」と「数値の郵便番号」のような型の食い違いを検出し、必要な変換まで下書きに含めます。実行してから型エラーで落ちる、を未然に防ぎます。
- サンプル値のパターン
名前だけでは判断しきれないとき、実際に入っている値の形(メール・電話番号・日付フォーマット等)を見て対応関係を推し量ります。名前が曖昧でも、中身が答えを教えてくれます。
この3つを根拠にするからこそ、AIの下書きは「それっぽい当てずっぽう」ではなく、人間がそのまま採用できる確度を持ちます。そして大事なのは、AIが自分の確信の度合いも一緒に申告するという点です。次の章につながります。
人間の仕事は「書く」から「承認する」へ
AIの下書きには、行ごとに 確信度(Confidence) が添えられます。「ほぼ確実」な行と「自信がない」行が、最初から色分けで見える状態になっているのです。
| 入力(Salesforce) | 出力(顧客マスタ) | 確信度 |
|---|---|---|
| Name | customer_name | 高 |
| BillingPostalCode | postal_code | 高 |
| Phone | tel | 高 |
| Industry | industry_category | 中 |
| AnnualRevenue | annual_sales | 高 |
すると人間は、すべての行を等しく見直す必要がなくなります。「高」の行はざっと流し、「中」の行だけ立ち止まって判断する。上の例なら、確認すべきは「Industry → industry_category」── マスタの値セットが揃っているか、という一点だけです。
これは、決定論的に処理できる部分と、人間の判断が要る部分を、機械が自分で仕分けして渡してくるということです。AIは「自分が確実なところ」と「人に委ねるべきところ」の線引きまで含めて下書きする。だから人間は、本当に判断が必要な数行だけにエネルギーを集中できます。
マッピングを全自動で確定してしまうと、間違いに気づくのは本番でデータが壊れてから。Passworkがあえて「下書き+人間の承認」という形をとるのは、速さと安全のどちらも捨てないためです。最後にOKを出すのは人間 ── この一線は意図的に残しています。
下書きは、使うほど良くなる
ドラフトファーストの効果は、回数を重ねるほど効いてきます。Passworkは、同じ組織で過去に確定したマッピングを学習し、似たケースで下書きに反映するからです。
- あるフローで「customer_id → cust_id」と確定した
- 別のフローで同じ「customer_id」が登場した
- AIは過去の判断を覚えていて、最初から「cust_id」を下書きに書く
これが意味するのは、「マッピングの判断が、個人の頭の中ではなく、組織の資産として溜まっていく」ということです。ベテランが下した判断は下書きの精度として残り、担当者が代わっても再現されます。属人化していた「あの人しか分からない対応付け」が、少しずつシステム側へ移っていく。
なぜ「下書き止まり」が、いちばん正しい設計なのか
ここまで読んで、こう思った方がいるかもしれません ──「そこまで賢いなら、いっそ全部AIに確定させればいいのでは?」
私たち Prazto は、あえてそうしません。これは技術的な限界ではなく、設計思想としての選択です。
データ連携は、一度動き出すと毎日・毎時間、淡々とデータを流し続けます。だからこそ 「決まったことは正確に、何度でも同じように実行される」 決定論的な土台が要ります。一方で、フィールドの意味を読み取る・表記の揺れを吸収するといった「あいまいさを扱う仕事」は、AIが圧倒的に得意です。
この2つを混ぜないことが肝心です。あいまいさを扱う部分(マッピングの下書き)はAIに、確実に繰り返す部分(確定したフローの実行)は決定論に。その境界に、人間の承認を一枚はさむ。これが私たちの考える、壊れにくいデータ連携の形です。

そして、この設計がきちんと回るためには、その手前に 地味だけれど決定的な土台 が要ります ── 業務そのものの理解、システム同士をつなぐ接続、そして決定論的に動く基盤の整備。AIに気持ちよく下書きをさせるには、入力と出力のフィールドが正しく取得でき、過去の判断が記録され、確定したフローが安定して回っている必要があるのです。
派手なのはAIの下書きですが、それを成立させているのは、この目立たない土台のほうです。そここそが、Passwork と Prazto がいちばん時間をかけている主戦場です。
まとめ:人は0→1を、AIは0→0.8を
項目マッピングは、ETL/データ連携のなかで最も単調で、最も人を疲れさせる工程でした。白紙を1行ずつ埋める作業に、知的な喜びはほとんどありません。
Passworkの「マッピング自動提案」は、その起点を「白紙」から「下書き」へ動かしました。
- AIが、名前・型・サンプル値を根拠に 一稿を書く
- 確信度を添えて、怪しい行を最初から見える化する
- 人間は 仕上げと承認 に集中する
- 確定した判断は 組織の資産 として下書きに還元される
「項目マッピングはAIが下書きする時代へ」── これは便利機能のキャッチコピーではなく、人とAIの仕事の分け方そのものの設計判断です。0→0.8はAIに任せ、最後の0.8→1という判断と責任の部分を人間が握る。その役割分担を、いちばん負担の大きかった工程から始める ── それがPasswork のマッピング自動提案です。



