


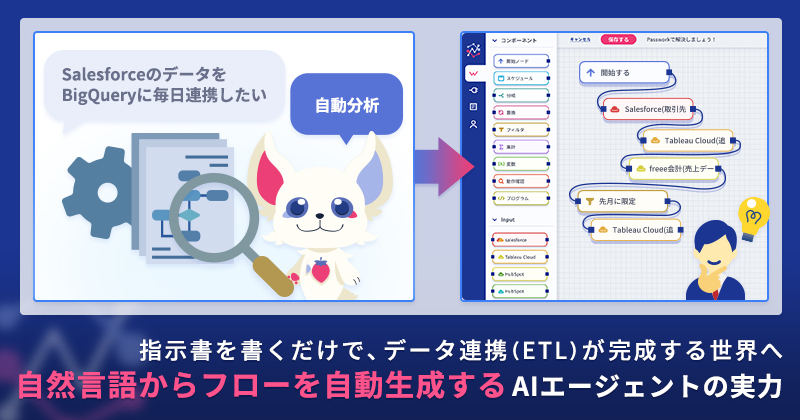
「毎日23時にSalesforceの商談データをBigQueryに同期したい」── そう書いた1枚の指示書から、データ連携フロー全体が自動的に立ち上がる時代がやってきました。本記事では、Passworkに搭載されたAIエージェント機能「指示書からのフロー作成」の動作原理と、実際の活用シーンを、構築デモとあわせてご紹介します。
01 なぜ「指示書からのデータ連携」が必要だったのか
ETL(データ連携)の構築には、長年「業務担当者が要件を語る → エンジニアが内容を理解して ツールで実装する」というステップが必要でした。
このプロセスは日本では一般的に見られる形ですが、様々な課題が生じているのが現状です。
- 業務担当者が要件を伝える時に、語彙の食い違いで 解釈ミス が発生する
- エンジニアが手戻りを恐れて 過剰に詳細仕様書 を求める
- 結果、「ちょっと連携を試したい」が 2〜3ヶ月待ちになる
- 業務担当者は「とりあえず手作業でCSV出して、Excelで結合する」運用を続けてしまう

そこに私たち Prazto が向き合ってきた問いがありました:
データ連携は、本当に「IT専門家にしか扱えない領域」のままでいいのか?
業務を一番よく知っているのは現場のひとです。要件をエンジニアに翻訳してもらわなくても、自分の言葉で書くだけで連携が立ち上がる ── その世界が作れたら、企業のデータ活用は段階を一つ駆け上がるはずです
これが、Passworkに「指示書からのフロー作成」機能を搭載した動機です。
02 従来のETL構築 vs AIによる指示書ETL ── 何が変わるのか
従来のETL構築と、AIによる指示書ETLでは、何が決定的に違うのでしょうか。両者を並べて比較してみます。
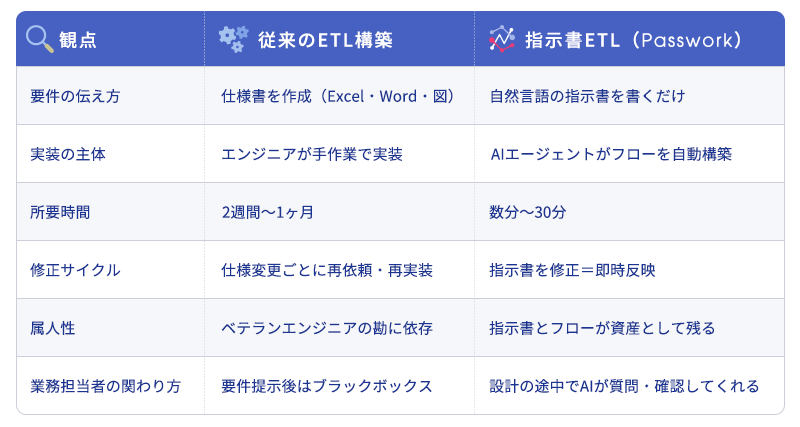
特に重要なのは 「修正サイクル」の差 です。従来のETLは、要件が変わるたびにエンジニアへの再依頼が必要でしたが、指示書ETLでは 指示書を書き直す=そのままフローが書き直される。これにより、業務変化への追従速度が桁違いに速くなります。
03 「指示書からのフロー作成」の動作原理
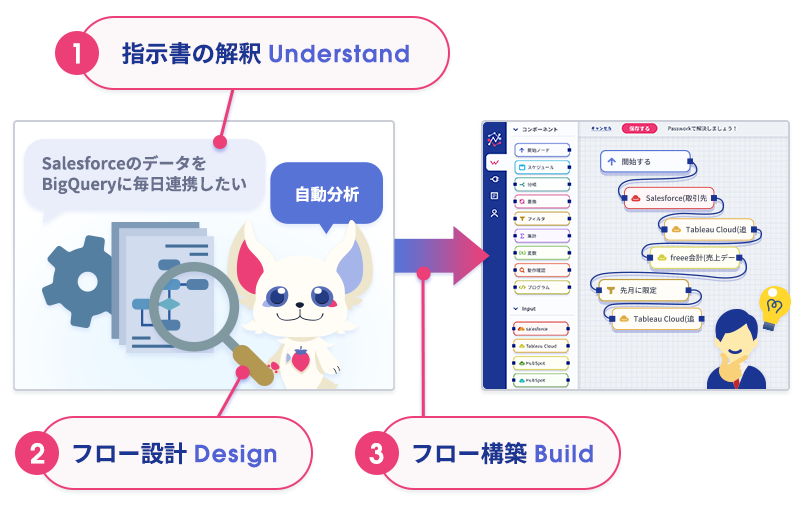
では、Passworkがどのように指示書からフローを生成しているのか、内部の動作を3ステップで解剖します。
- 指示書の解釈(Understand)
AIエージェントは指示書を読み、「何を、どこから取得し、どう加工して、どこに出力するか」「いつ、どんなトリガーで動くか」を構造化された設計図に落とし込みます。情報が足りない箇所は、ユーザーに自然な日本語で質問してくれます。- フロー設計(Design)
設計図をもとに、入力ノード/変換ノード/出力ノード/スケジュールノードを 論理的に必要な構成 として組み立てます。コネクタの選定、フィールドのマッピング自動提案、変換ロジックの推論まで自動で行います。- フロー構築(Build)
設計したフローを Passworkのキャンバス上に そのまま編集可能なノード群 として配置します。生成されたフローは、ユーザーが微調整して即実行できます。
大事なポイント
AIエージェントは「全部任せろ」型ではなく、必要な確認はちゃんと聞いてくる設計です。「コネクタはどれを使いますか?」「対象テーブルは accounts でよろしいですか?」── こうした重要な意思決定は、必ずユーザーに確認してから反映されます。
04 実例:Salesforce → BigQuery 連携を、たった1枚の指示書で
ここから具体的なシーンを見てみましょう。Salesforceの商談データを、毎日BigQueryに差分同期したい── という典型的なETL要件を、指示書1枚で構築します。
① 業務担当者が書いた指示書
まず、業務担当者がPassworkに入力した指示書がこちらです。専門用語ではなく、自然な業務言語で書かれています。
■ フロー名: Salesforce商談データ → BigQuery差分連携
■ 目的
Salesforceの商談(Opportunity)データをBigQueryに連携して、
Tableauなどから分析できるようにする。
■ データ取得元
- サービス: SalesforceのOpportunity(商談)
- 取得条件: 前回実行時以降に更新されたレコード(差分取得)
- 取得する情報: Id, 商談名, フェーズ, 金額, 完了予定日, 担当営業
■ データ出力先
- サービス: BigQueryのsalesforce_data
- テーブル名は適切な名称
- その他: 新規は新規、同じものは更新
■ スケジュール
- 毎日 午前1時に自動実行ご覧の通り、エンジニア向けの仕様書ではなく、業務担当者が普段の業務会話で使う言葉そのままで書かれています。これが Passwork の「指示書からのフロー作成」が受け取る入力です。
② AIエージェントが解釈した内容
Passworkに指示書を投入すると、AIが内容を構造化して画面に提示してくれます。ここで業務担当者は、AIの解釈が正しいかを確認できます。
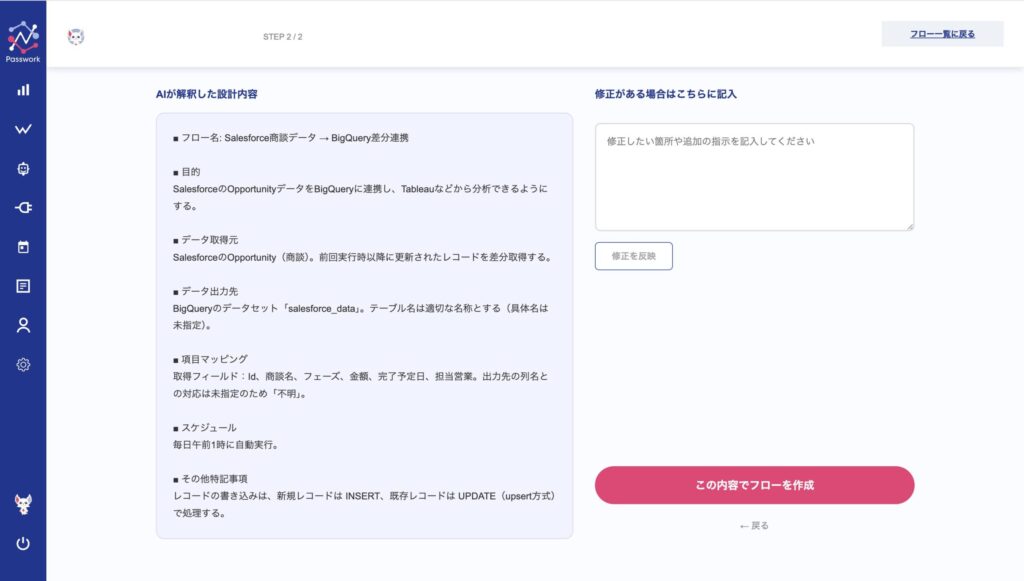
■ フロー名: Salesforce商談データ → BigQuery差分連携
■ 目的
SalesforceのOpportunityデータをBigQueryに連携し、Tableauなどから分析できるようにする。
■ データ取得元
SalesforceのOpportunity(商談)。前回実行時以降に更新されたレコードを差分取得する。
■ データ出力先
BigQueryのデータセット「salesforce_data」。テーブル名は適切な名称とする(具体名は未指定)。
■ 項目マッピング
取得フィールド:Id、商談名、フェーズ、金額、完了予定日、担当営業。出力先の列名との対応は未指定のため「不明」。
■ スケジュール
毎日午前1時に自動実行。
■ その他特記事項
レコードの書き込みは、新規レコードは INSERT、既存レコードは UPDATE(upsert方式)で処理する。AIエージェントが不足している内容を補い、実行に適した形へと整えてくれます。
③ フローが自動・対話的に構築されていく
ユーザーが「この内容でフローを作成」をクリックすると、AIエージェントがキャンバス上にフローを構築していきます。各ノードを配置し、接続し、コネクタを選定し、設定値を埋めていく ── このプロセスを、ユーザーは サイドバーが開いた状態でリアルタイムに観察 できます。
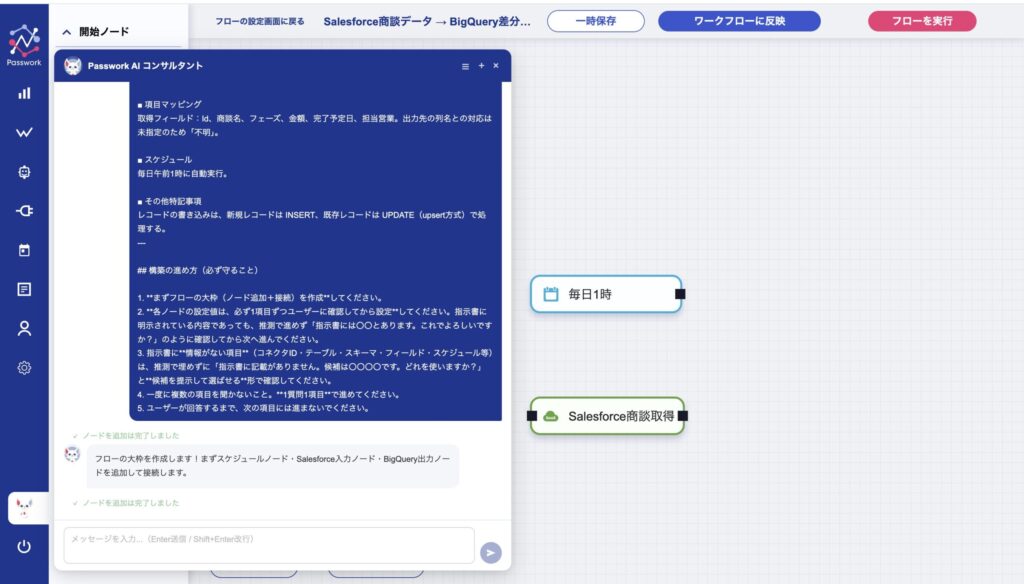
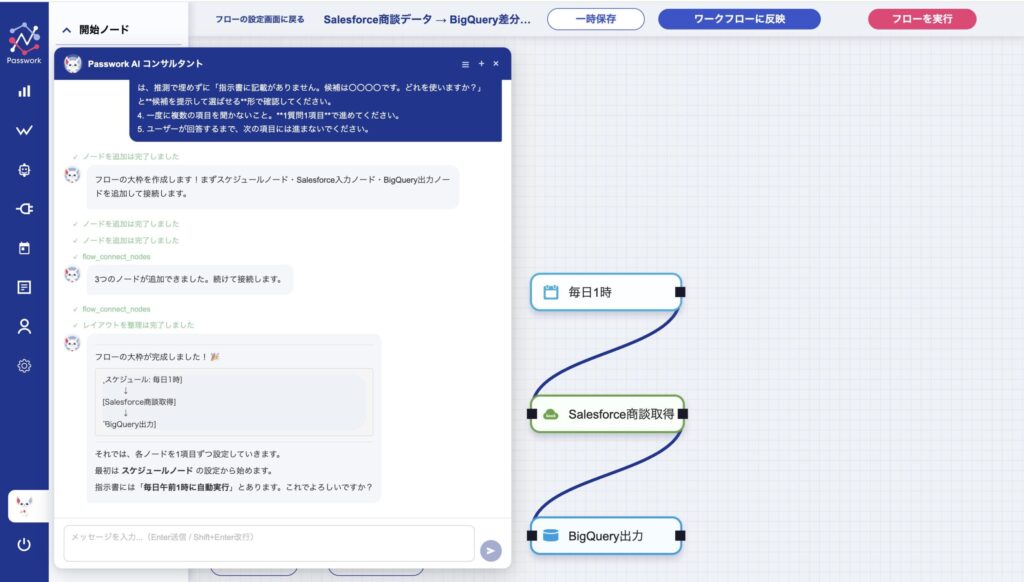
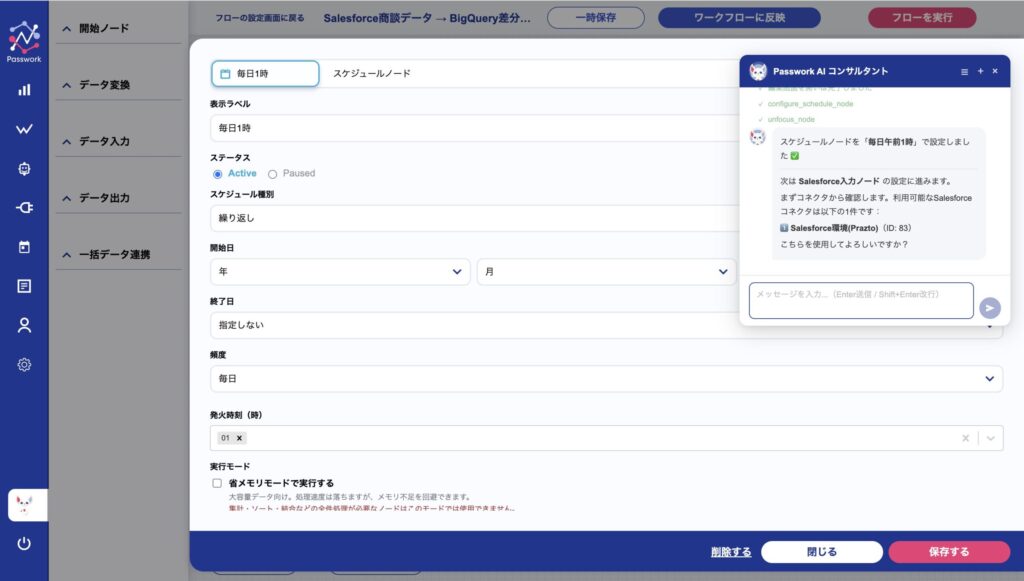
30分後にできあがったフローは、人間のエンジニアがプログラムで2週間かけて作るものと同等の品質。業務担当者ひとりが、指示書1枚を書くだけで完成しました。
05 指示書を書くときの3つのコツ
「指示書からのフロー作成」を最大限に活用するには、ちょっとしたコツがあります。実際のプロジェクトで効果が高いものを3つご紹介します。
- コツ1:データの「流れ」を時系列で書く
「どこから取って → どう変えて → どこに出すか」を時系列に沿って書くと、AIが解釈ミスをしにくくなります。要件をブロック単位で並べる形式(取得元・出力先・スケジュール…)が最も伝わります。
- コツ2:サービス名などは具体的に書く
「Salesforce」「BigQuery」「kintone」「freee」── こうしたサービス名・オブジェクト名・フィールド名は具体的に記載した方が良いです。Passworkのコネクタ群はシステム側で記憶されているので、具体的なサービス名があるほど精度が上がります。
- コツ3:曖昧な箇所はAIに任せる
「具体的なフィールドはまだ決まっていない」「マッピングは可能な限りで」── こうした曖昧さは、無理に詰めずに 「可能な限りすべて」「指定なし」 と書いて構いません。Passworkは、構築途中で必要な意思決定をユーザーに質問してくれます。
06 AIが自動構築するフローの中身
AIが指示書から組み立てたフローは、エンジニアが手で組んだものと同じ構造を持っています。Passwork上で完全に編集可能で、ノードの追加・削除・設定変更も自由に行えます。
具体的には、以下のような要素を自動で配置・設定します。
- スケジュールノード ── 開始日や頻度を設定
- 入力ノード ── 適切なコネクタを選定し、対象オブジェクト・フィールド・取得条件を設定
- 変換ノード ── 必要に応じてフィルタ・結合・整形を配置
- 出力ノード ── 出力先のコネクタ・テーブル・オペレーション(Insert/Upsert)を選定
- 項目マッピング ── 入力フィールドと出力フィールドの対応を、AIが意味的に推論して自動マッピング
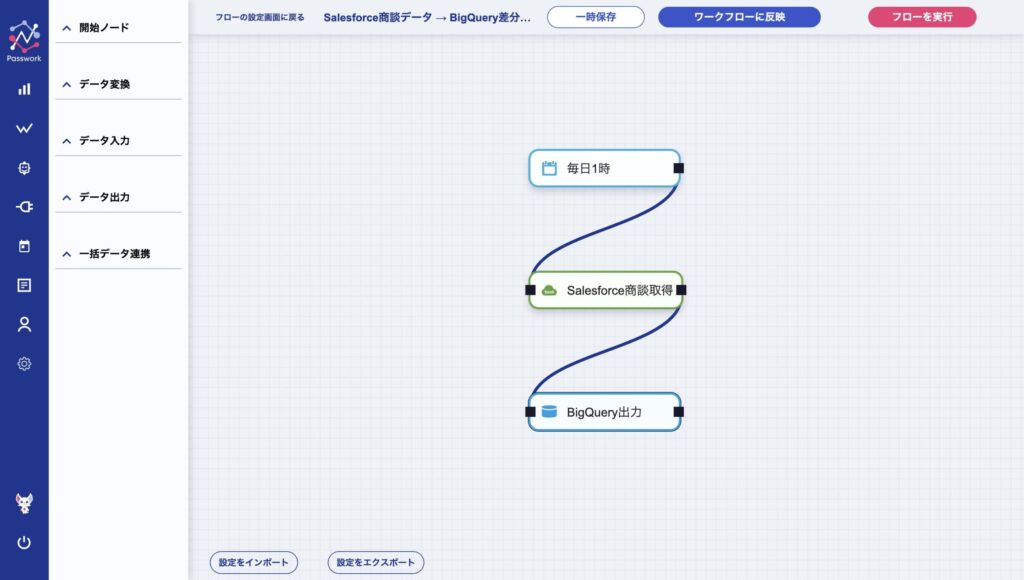
AIが構築したフローは、Passwork本体の標準機能(スケジュール実行・実行履歴・エラー通知・AIによるエラー分析)にすべて対応しています。指示書ETLは「例外対応も含めて、本番運用にそのまま乗せられる」品質を持っているということです。
「指示書からETLが組み立つ」という Passwork の思想は、AIエージェントを業務で機能させるための「決定論」レイヤーを成立させる土台でもあります。AIエージェント全体の設計論については、AIエージェントが業務で機能する条件 で詳しく解説しています。
07 まとめ:データ連携を、IT専門家から現場のひとりひとりへ
データ連携は、これまで 一部のIT専門家にしか扱えない領域 でした。それが業務とITの間に生まれる「翻訳コスト」となり、企業のデータ活用速度を構造的に律速していました。
Passworkの「指示書からのフロー作成」は、その翻訳コストをゼロに近づける挑戦です。
- 業務担当者が 自分の言葉で書くだけで、フローが立ち上がる
- エンジニアの工数を ゼロ〜最小 にできる
- 業務変化への追従が 「指示書を書き直すだけ」 で完結する
- 属人化が解消され、指示書とフローが組織の資産 として残る
これは「便利機能の追加」ではなく、データ連携という業務領域そのものの民主化 を目指した取り組みです。AIエージェントが業務を自走で代行する時代に、データ連携を「現場のひとりひとり」が扱える世界 ── これが、私たちが Passwork に込めている挑戦です。
また、ETLはAI で作れるようになっても、運用フェーズで突然エラーが出たときの対応コストはまだ高いままです。Passworkはこの2つを「作る」と「直す」のペアでAI化を行っていて、運用側の伴走者は別記事で扱っていますのでご覧ください。https://passwork.prazto.com/article/ai-error-analysis
ご紹介した機能の一覧はPassworkの機能ページからご覧いただけます。料金プランはこちら



