離反リスク顧客をHubSpotに自動登録する仕組みの構築
HubSpotをご利用の企業様では、業務で蓄積されている顧客情報を活用して、様々なシナリオで自動的にHubSpotへの登録とメール配信を実現したいというニーズがあるのではないでしょうか。
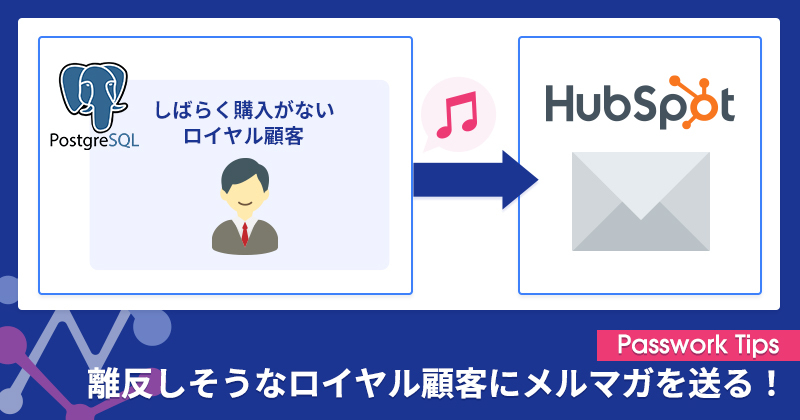
例えば、基幹システムに顧客情報と購買データが蓄積されている場合を考えてみましょう。このデータを分析すれば、「ロイヤル顧客層のうち、直近3ヶ月以上購入履歴がない顧客リスト」を抽出することが可能です。これらの顧客は自社にとって重要な大口顧客でありながら離反リスクが高い状態にあるため、リテンション施策としてのメールマーケティングやリエンゲージメント施策を実施したいところです。
しかし、こうした顧客リストの抽出と更新作業が手動での運用に依存していると、業務負荷の問題から結果的に施策が実行されないという課題に直面することが多いのが現実です。
今回は、このような課題に対してPassworkを活用し、離反リスク顧客を自動的にHubSpotに登録する仕組みの構築方法をご紹介します。まずは、実際の操作がどれほど直感的に行えるかを動画でまとめましたので、ぜひご確認ください。
連携元と連携先システムの事前設定
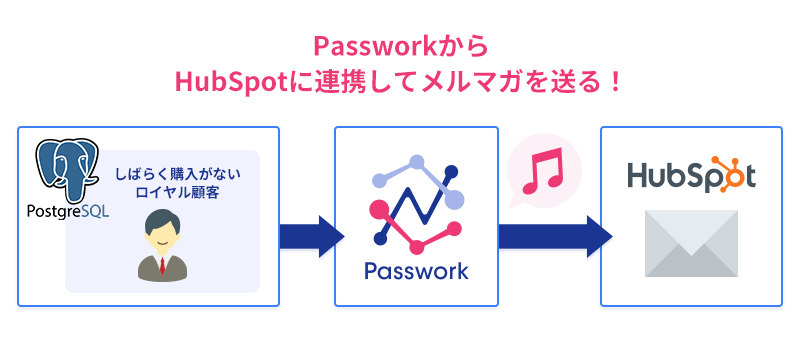
それでは、離反リスク顧客の自動登録システムを構築していきましょう。まず、Passworkで連携するシステムとして、データベース側とHubSpot側の設定を行います。
データベースに「3ヶ月以上購入がない顧客一覧」のViewを作成
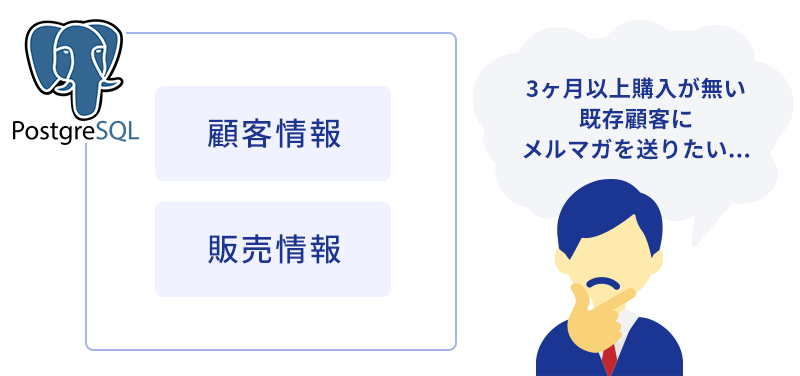
現在、PostgreSQLが以下の構成で運用されているものとします。


この2つのテーブルを使用して、以下のSQLで「3ヶ月以上購入がない顧客一覧」をViewとして作成します。
CREATE VIEW product.churn_risk_customers AS
SELECT c.customer_id,
c.last_name,
c.first_name,
c.email,
max(p.purchase_at) AS last_purchased_at,
sum(p.total_amount) AS total_amount
FROM product.customers c
JOIN product.purchases p ON p.customer_id::text = c.customer_id::text
GROUP BY c.customer_id, c.last_name, c.first_name, c.email
HAVING max(p.purchase_at) < (now() - '3 mons'::interval);これでPostgreSQL側の準備が完了しました。以下が実際に作成されたViewの内容です。
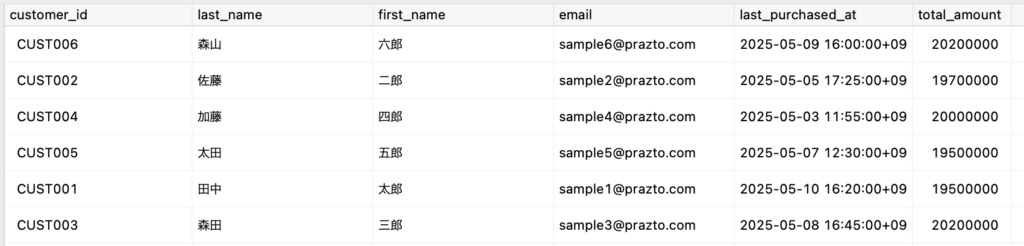
(churn_risk_customers)
HubSpotでのメルマガ送信用リスト作成
次に、データの受け皿となるHubSpot側で、離反リスク顧客を管理するためのリストを作成します。
これで連携に必要な基本システム構成が完成しました。今回のコンセプトは、これらのシステムをPassworkで接続し、データが自動的に連携される仕組みを構築することです。
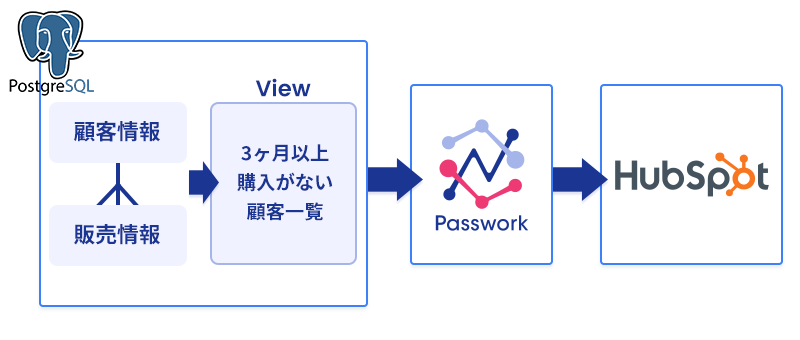
システム構成を簡単に図示すると上記のようになります。Passworkの特徴は、大規模なシステム開発を行うことなく、このような自動連携の仕組みを迅速に構築できる点にあります。
Passworkでの連携処理構築
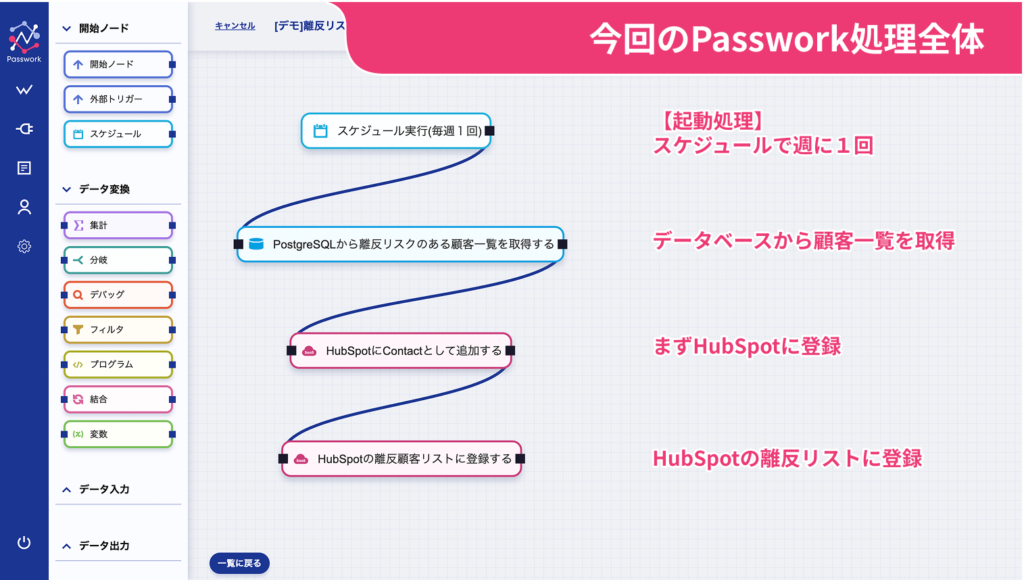
それでは、Passworkを使用して実際の連携処理を構築していきましょう。上記の画像が今回構築する処理の全体像となります。この4ステップで非常に簡潔に構成されており、直感的で理解しやすい構成になっています。
処理は以下の4ステップで構成されています:
- ①起動処理
- ②データベースから顧客一覧を取得
- ③HubSpotへの顧客情報登録
- ④HubSpotの離反リストへの登録
それでは、各ステップの詳細設定について順次確認していきましょう。
【Step1】スケジュール設定
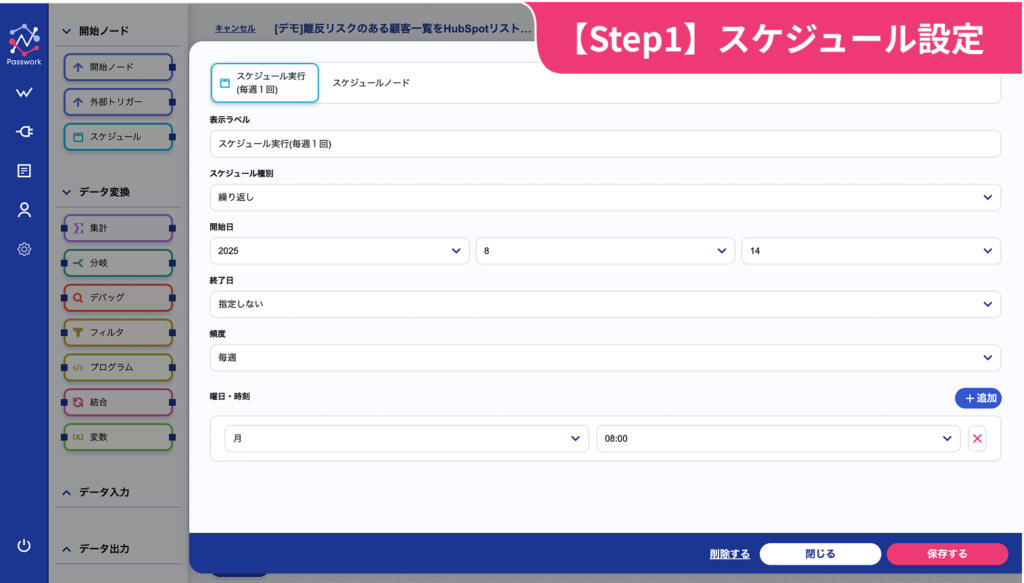
まず、処理の実行方法を定義します。定期実行か、特定のイベントをトリガーとした実行かを選択できます。今回の要件では、週1回のHubSpot更新が適切であるため、そのように設定しています。
Passworkでは、月単位での日付指定実行、週単位での曜日指定実行、日単位での時間指定実行が選択可能です。今回は毎週月曜日の朝8時に実行するよう設定しています。
【Step2】PostgreSQLからのデータ取得
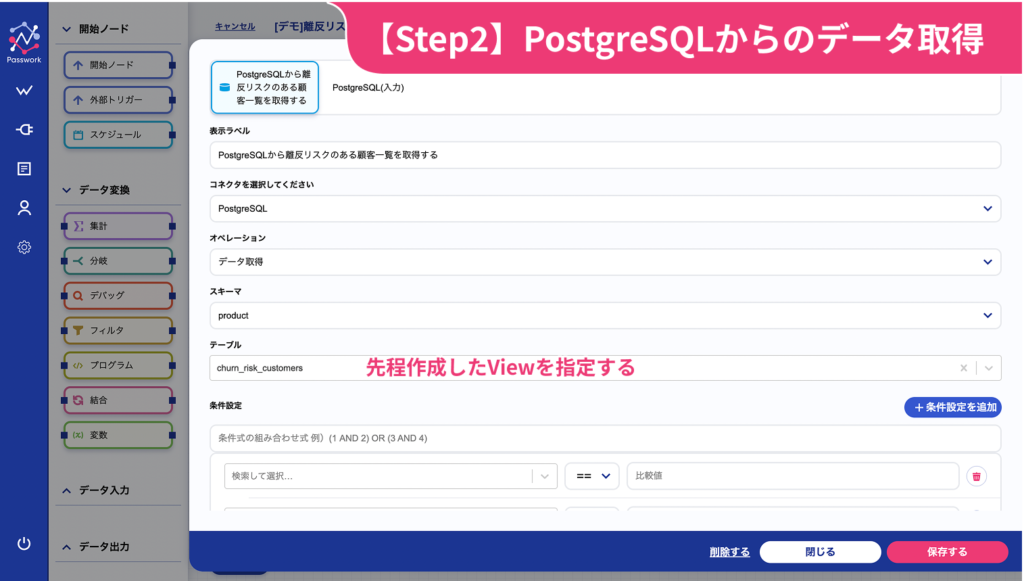
次に、離反リスク顧客一覧を取得します。先ほど作成したPostgreSQLのViewを指定する設定です。事前にPostgreSQLへの認証をコネクタで設定済みのため、スキーマやViewが自動的に選択リストに表示されます。複雑な設定は不要で、直感的な選択操作で完了します。
【Step3】PostgreSQLから取得したデータをHubSpotのContactとして登録
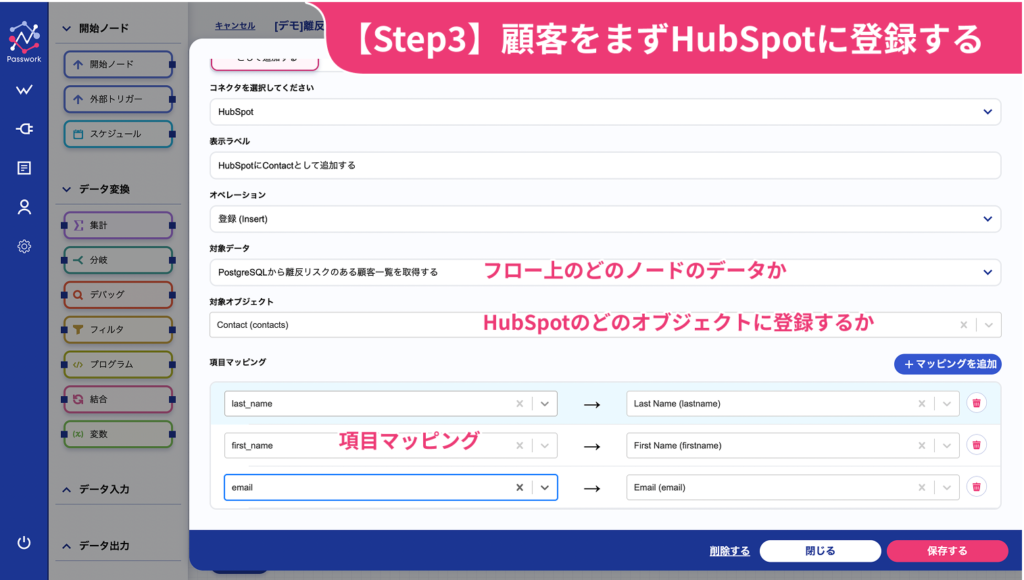
取得した顧客データがHubSpotのContactとしてまだ登録されていない場合、リスト追加前にContactとして先に登録する処理です。この設定も直感的に行えるよう設計されています。まず、入力データソースについては、フロー画面上の「データを保持するノード一覧」から選択します。
次に「HubSpotのどのオブジェクトに登録するか」についても、自動表示される選択肢から選ぶだけで設定できます。項目マッピングでは、PostgreSQLのView項目とHubSpotのContact項目をマッピングしますが、左右それぞれに項目一覧が自動表示されるため、選択するだけで設定が完了します。
【Step4】HubSpotの離反顧客リストに追加
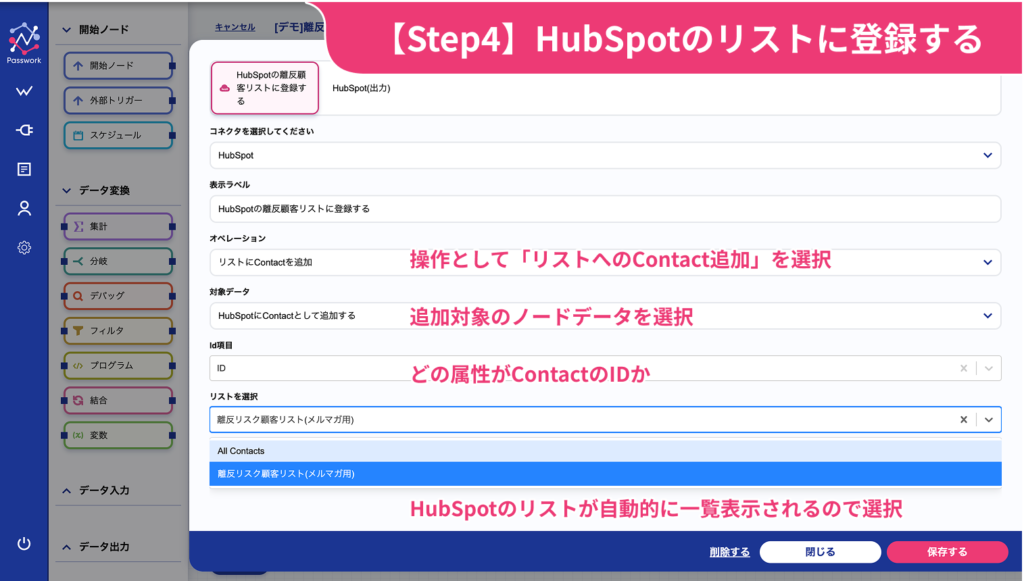
最終ステップとして、離反顧客リストへの顧客追加を行います。HubSpotの操作メニューから「リストへのContact追加」を選択し、前ステップと同様に追加対象データ(ノード)を選択して、キーとなるID属性を指定します。
最後に、追加先となるHubSpotのリストを選択しますが、これも自動でリスト一覧が表示されるため、選択するだけで設定完了です。
以上が今回のフロー設定の全手順ですが、大規模なシステム構築は一切不要で、この4ステップのみで完了します。
PassworkはHubSpotの各種プランに対応
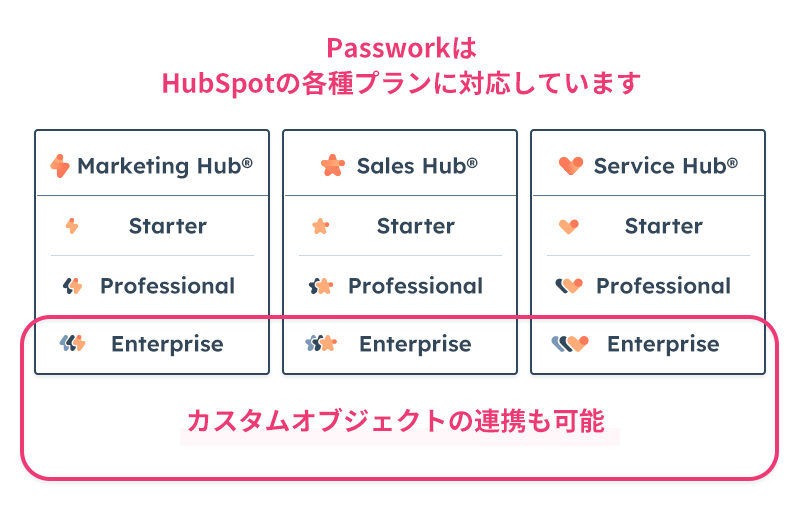
HubSpotは、Marketing Hub、Sales Hub、Service Hubといった豊富な製品ラインナップで構成されていますが、Passworkはこの3つの製品すべてに対応しています。また、Enterprise Planで利用可能なカスタムオブジェクトについてもPassworkで連携することが可能です。
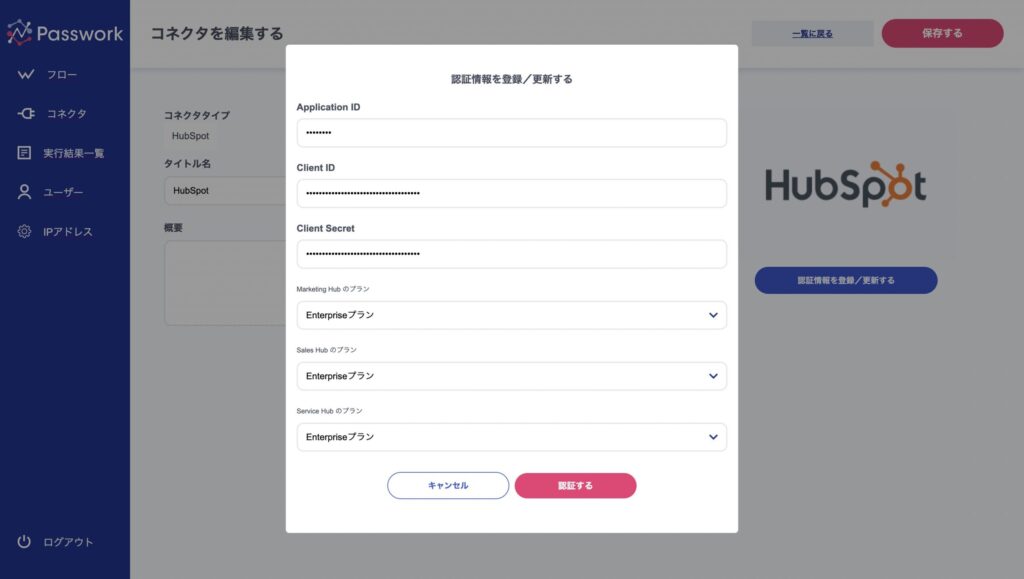
これらの製品やプランの違いについても、直感的な設定で対応できるよう設計されています。下記のコネクタ認証画面では、お客様それぞれの製品やプランを設定できるようになっており、この保存された設定情報に基づいて、Passworkが背後で自動的に処理を調整します。そのため、ユーザーは製品やプランの違いを特に意識することなく、スムーズに連携設定を行うことができます。
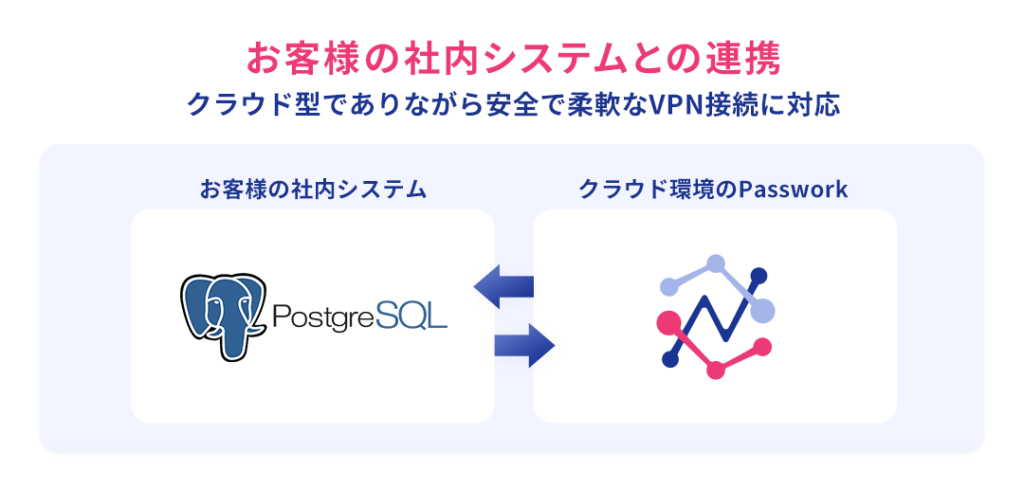
【よくある質問】プライベートネットワーク内PostgreSQLへの接続について
PassworkはクラウドベースのETLサービスであるため、お客様のデータベースがプライベート環境に設置されている場合の接続可否について、よくご質問をいただきます。
Passworkの契約プランがProfessional Plan以上の場合、VPNやVPCピアリング接続を通じて、Passwork環境とお客様環境との接続が可能となります。そのため、プライベートネットワーク内に配置されたPostgreSQLについても、接続条件を満たせば連携することができます。
実際の導入事例として、AWSのVPC環境とVPCピアリング接続を活用した接続実績もございます。詳細については下記の取材事例をご参照ください。
まとめ
今回は、PostgreSQLに蓄積されている離反リスク顧客のデータを、HubSpotのリストへ自動登録する処理をご紹介いたしました。大規模なシステム構築を必要とせず、直感的な4ステップの設定のみで連携を実現できる様子をご確認いただけたのではないでしょうか。
Passworkでは、この連携事例に限らず、「大規模な仕組みを必要とせずに連携を実現する」「直感的な操作により、ITに詳しくない担当者でも設定を完了できる」という2つの方針をコンセプトにサービスを構築しています。これにより、ビジネスユーザーはIT部門のサポートを必要とせず、自ら設定や変更を行うことが可能になります。
データ連携に関してお困りの方は、ぜひ弊社までお気軽にお問い合わせください。